Data backup continues to become increasingly critical, paralleling the rise in frequency of data corruption events, natural disasters, systems failures, and other data-loss catastrophes.
When data needs to be restored, organizations may need to roll back weeks or even months to find a readable copy based on when the corruption or deletion occurred. In addition, industry and government regulations (e.g., Sarbanes-Oxley, HIPAA, GLBA, etc.) are becoming more stringent. All of these imperatives combined are driving the need to keep many weeks, months, and years of backup retention.
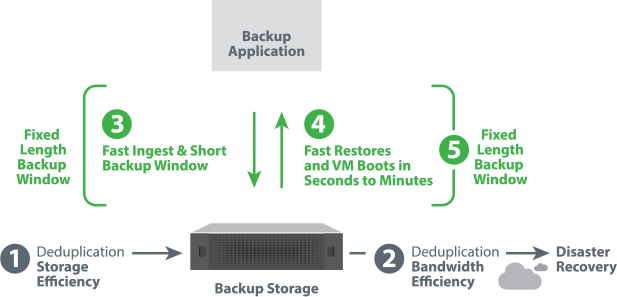
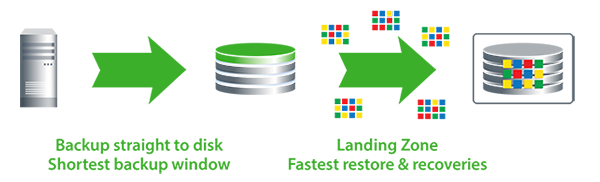
Using straight disk for backup storage becomes cost prohibitive very quickly. For example, keeping 12 weeklies as well as monthlies for 3 years equals 45 backup copies. Due to backup retention requirements, data deduplication is necessary. Not only will deduplication greatly reduce backup storage, it will also reduce WAN replication to the disaster recovery (DR) site because only the changes from backup to backup are stored and replicated.
Data deduplication compares the amount of storage required with data deduplication enabled to the amount of storage required without data deduplication, and the result is the “deduplication ratio.” If 20 copies of a 50TB backup are kept without data deduplication, 1PB of storage is required. The longer the retention period, the greater the storage required and, therefore, the greater the savings if data deduplication is used. For example, at 20 weeks of retention, a solution with data deduplication uses only 50TB to store 20 copies of a 50TB backup. The deduplication ratio is calculated as 1PB (without data deduplication) divided by 50TB (with data deduplication), which equals 20 and results in a deduplication ratio of 20:1.