ExaGrid understands that both backup and restore performance are crucial to backups, but that long-term storage costs for longer retention is crucial as well. Data deduplication is required, but how you implement it changes everything in backup.
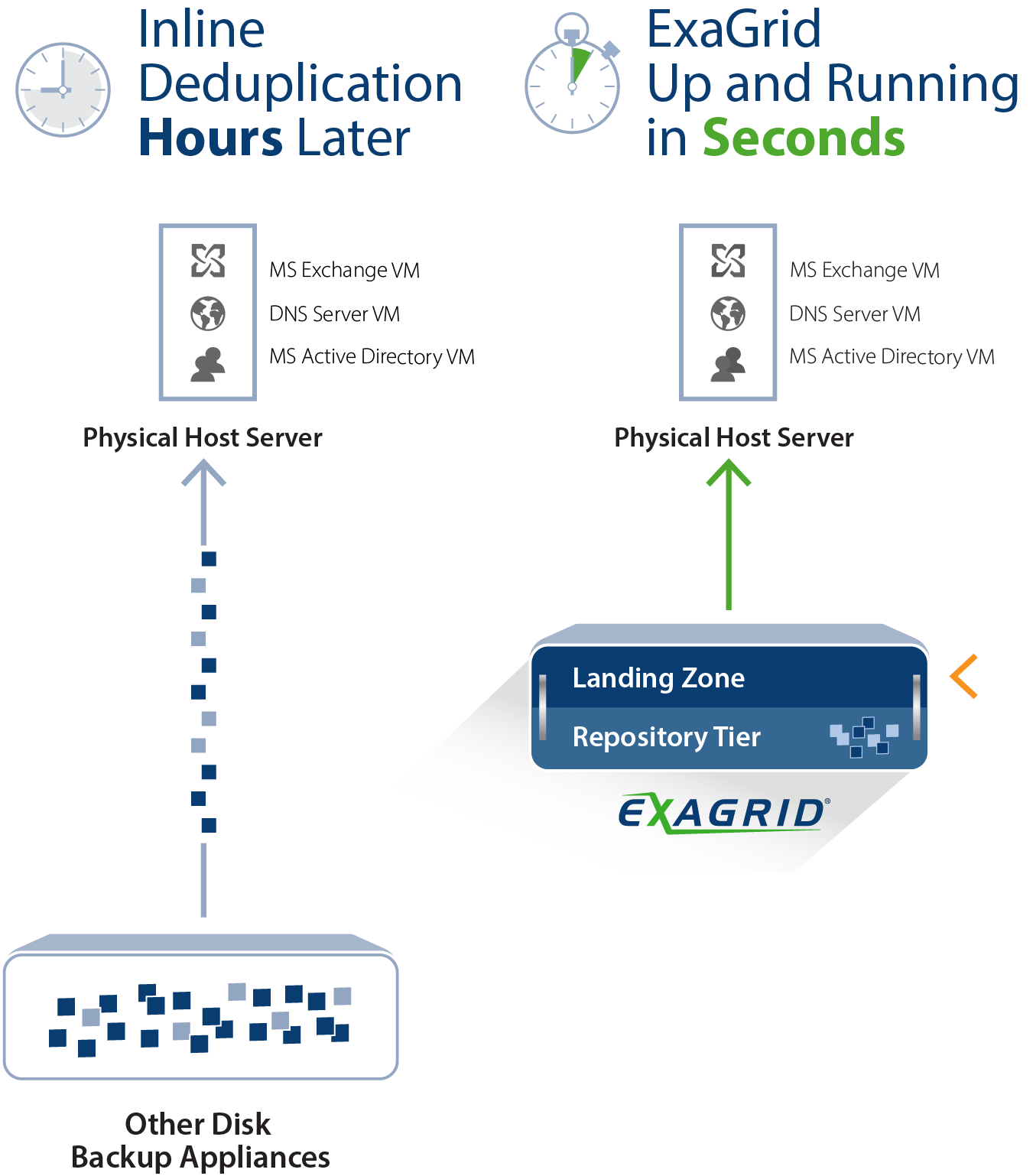
Data deduplication reduces the amount of storage required and also the amount of bandwidth for replication; however, if not implemented correctly, it will dramatically slow down backups, slow down restores and VM boots, and the backup window will grow as data grows. This is due to the fact that data deduplication is highly compute intensive; you don’t want to perform deduplication during the backup window and you also don’t want to restore or boot from a pool of deduplicated data.
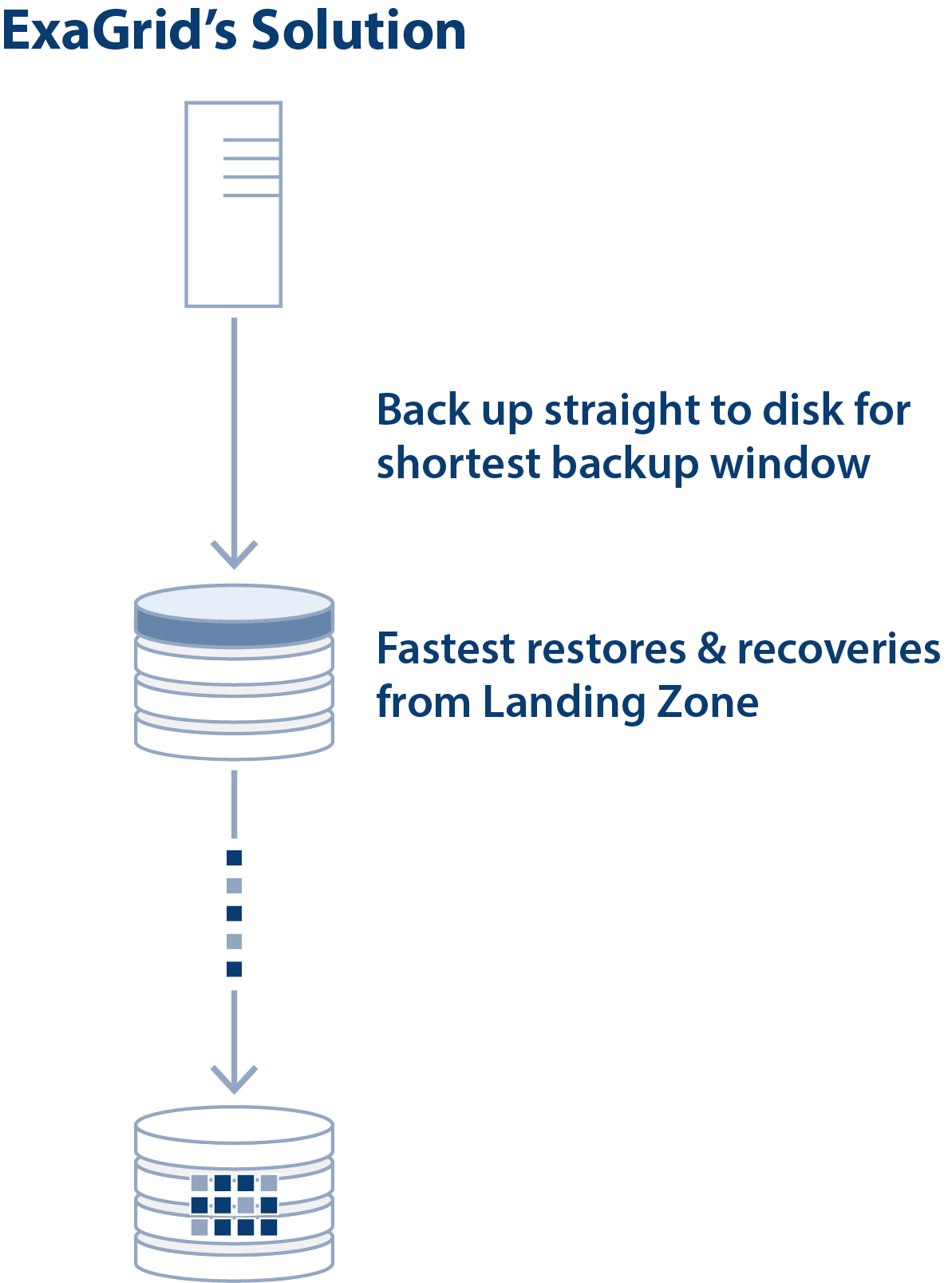
ExaGrid’s Tiered Backup Storage provides the fastest backup and restore performance with a disk-cache Landing Zone. In addition, ExaGrid provides a tiered long-term retention deduplicated data repository with the best level of data deduplication.
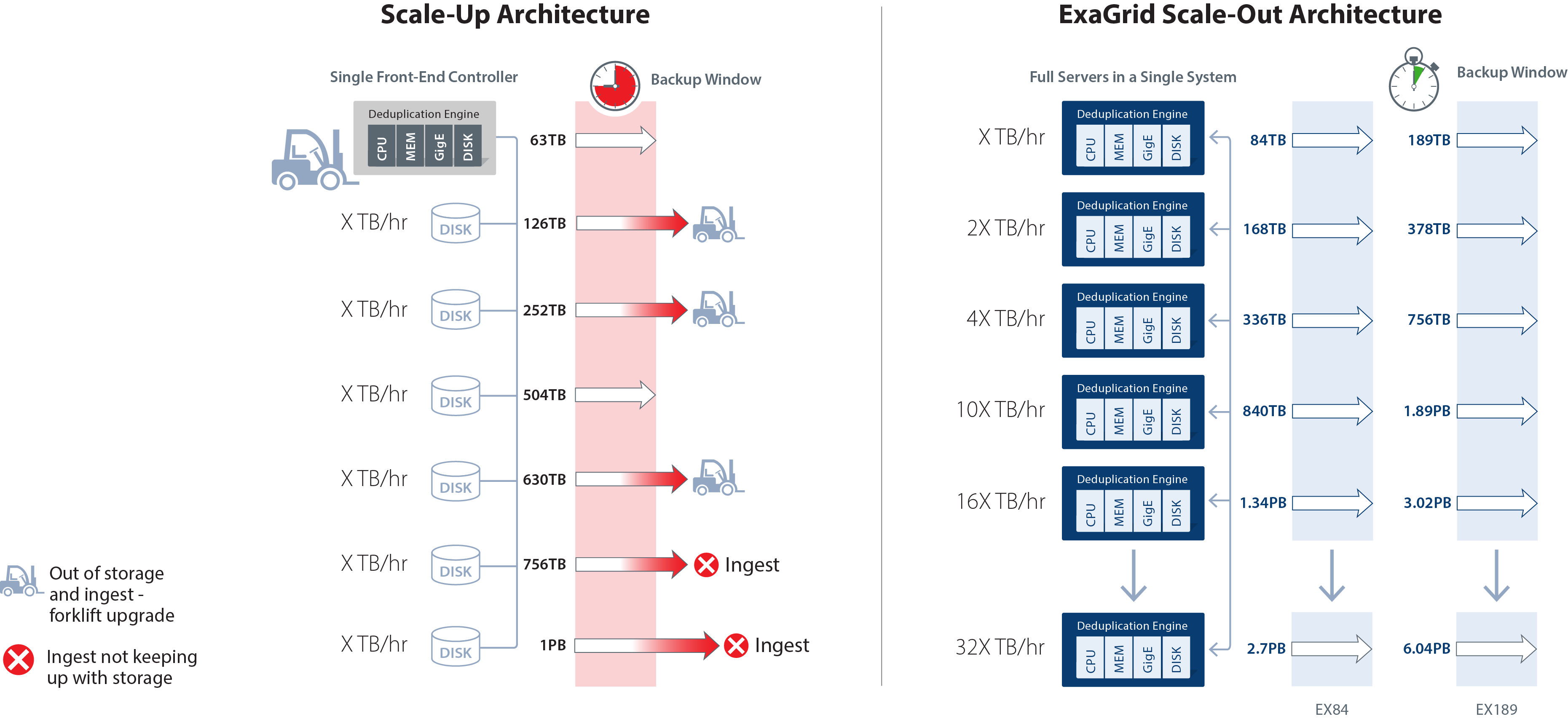
The combination of a disk-cache Landing Zone tiered to a long-term retention repository with deduplicated data provides 6X the backup performance and up to 20X the restore and VM boot performance over traditional inline deduplication appliances. ExaGrid’s Tiered Backup Storage with a disk-cache Landing Zone lands backups straight to disk without any inline deduplication processing. Backups are fast and the backup window is short. Deduplication and offsite replication occur in parallel with the backups and never impede the backup process as they are always second order priority. ExaGrid calls this “Adaptive Deduplication.”